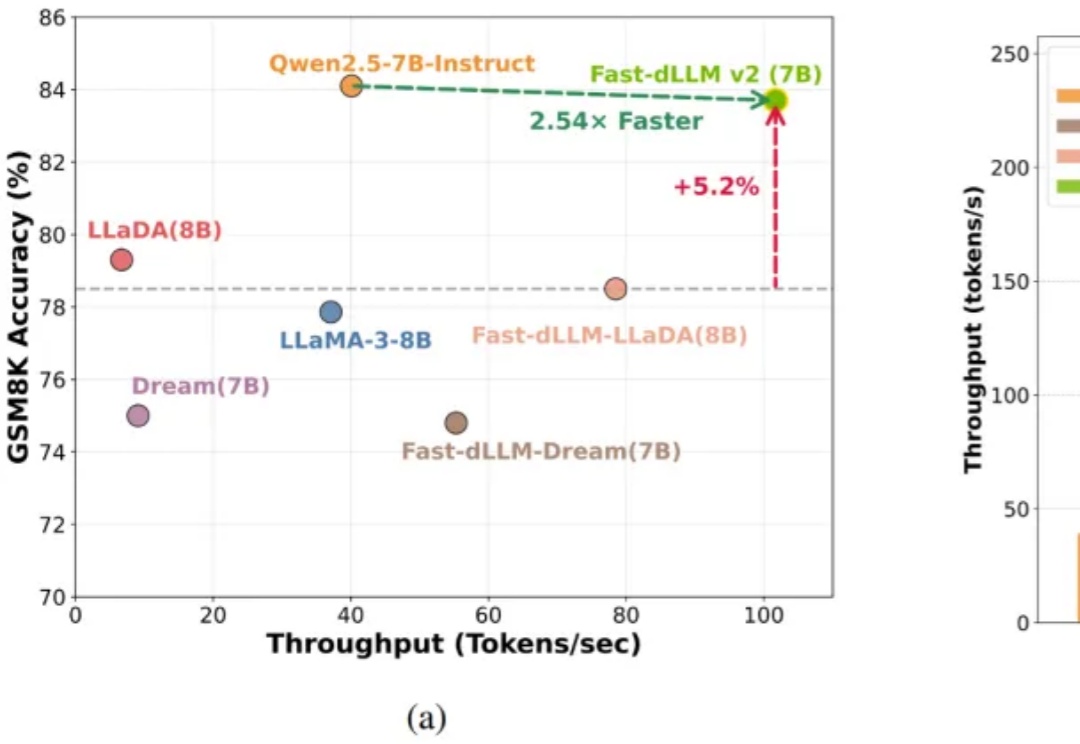
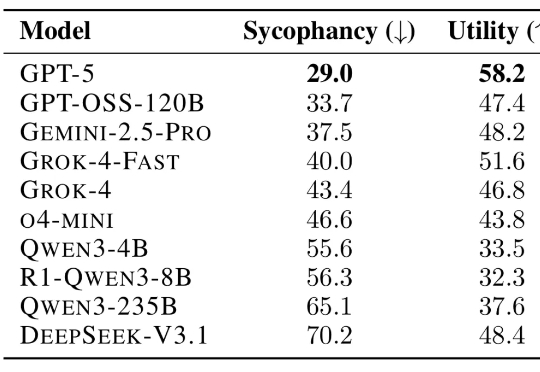
IEEE | LLM Agent的能力边界在哪?首篇「图智能体 (GLA)」综述为复杂系统构建统一蓝图
IEEE | LLM Agent的能力边界在哪?首篇「图智能体 (GLA)」综述为复杂系统构建统一蓝图LLM Agent 正以前所未有的速度发展,从网页浏览、软件开发到具身控制,其强大的自主能力令人瞩目。然而,繁荣的背后也带来了研究的「碎片化」和能力的「天花板」:多数 Agent 在可靠规划、长期记忆、海量工具管理和多智能体协调等方面仍显稚嫩,整个领域仿佛一片广袤却缺乏地图的丛林。
来自主题: AI技术研报
8569 点击 2025-11-10 09:20